Database for
AI Developers
A lightweight NoSQL database with vector search, TOON format, and enterprise security built-in
Need detailed instructions? View full macOS guide →
Save 40-50% on LLM Costs
TOON (Token-Oriented Object Notation) reduces token usage for GPT-4, Claude, and other LLM APIs
[
{
"_id": "abc123",
"name": "Alice Johnson",
"email": "alice@example.com",
"age": 28,
"city": "San Francisco",
"role": "engineer"
},
{
"_id": "def456",
"name": "Bob Smith",
"email": "bob@example.com",
"age": 34,
"city": "New York",
"role": "manager"
}
]collection: users
documents[2]{_id,name,email,age,city,role}:
abc123,Alice Johnson,alice@example.com,28,San Francisco,engineer
def456,Bob Smith,bob@example.com,34,New York,manager
count: 240-50% Cost Savings
Reduce LLM API costs by 40-50%. For 1M API calls, save $400-500 on GPT-4 or Claude.
Faster Processing
Less data means faster LLM responses. Get your results quicker with smaller payloads.
More Context
Fit more data in token limits. Perfect for RAG systems and long-context applications.
Your Data,
Your Terminal
MySQL-like interactive CLI built in Rust. Zero dependencies, lightning fast, works everywhere.
$ nexa -u root -p
Password: ********
Connected to NexaDB v3.0.4
Binary Protocol: localhost:6970
Multi-Database Architecture ✓
nexa(default)> databases
✓ Found 3 database(s):
[1] default
[2] analytics
[3] production
nexa(default)> use_db analytics
✓ Switched to database 'analytics'
nexa(analytics)> collections
✓ Found 3 collection(s):
[1] events (1,000,000 docs)
[2] users (50,000 docs)
[3] metrics (250,000 docs)
nexa(analytics)> use events
✓ Switched to collection 'events'
nexa(analytics:events)> query {"type": "purchase"}
✓ Found 125,000 documents
nexa(analytics:events)> create_db staging
✓ Database 'staging' created
nexa(analytics:events)> help
Database: databases, use_db, create_db, drop_db
Collection: collections, use, create, query, update,
delete, count, vector_search, help, exitBuilt for Developers
Try Vector Search
Search naturally. No exact keywords needed. This is what vector search does.
How Much Can You Save?
Calculate your LLM cost savings with TOON format
TOON (Token-Oriented Object Notation) removes redundant JSON formatting, reduces field name repetition, and uses compact syntax. Your data becomes 40-50% smaller, which means 40-50% fewer tokens sent to LLM APIs. You can use TOON with jsontooncraft (any database) or get built-in export in NexaDB.
Pricing data from vellum.ai/best-llm-for-coding (Jan 2025)
Everything You Need
LLM optimization, vector search, admin panel - all included. No extra tools needed.
Vector Search Built-in
HNSW algorithm for semantic search. 200x faster than linear scan. No need for separate Pinecone/Weaviate. Perfect for RAG and AI apps.
Binary Protocol (10x Faster)
Custom binary protocol on port 6970 is 10x faster than JSON REST APIs. Most databases only have slow HTTP/JSON. We have both.
Zero Config Setup
brew install nexadb → nexadb start → Done! No configuration files, no setup wizards, no Docker required. Pure Python, works everywhere.
Lightning Fast Queries
Advanced indexing (B-Tree, Hash, Full-text) delivers 100-200x speedup. <1ms lookups, 20K reads/sec. Fast enough for real apps.
TOON Export (Convenience)
Built-in TOON export for 40-50% LLM cost savings. Just convenience - you can use jsontooncraft or any TOON library with your JSON data.
Beautiful Admin Panel
Gorgeous UI out of the box. Query editor, TOON export, real-time monitoring. Dark/light themes. No extra tools needed.
Secure by Default
Built-in encryption, RBAC, API keys, and audit logging. Secure enough for production without complex setup. MongoDB-inspired security model.
Fast Enough for Real Apps
Not trying to beat PostgreSQL. Just fast enough for MVPs and production apps with thousands of users.
Speed Improvements
Real Numbers
Built on Solid Foundations
Enterprise-grade architecture designed for performance, reliability, and scale
Performance Engine
Storage & Indexing
AI & Vector Search
Reliability & Durability
Query Optimization
Security & Access Control
Why NexaDB is Production-Ready
Benchmarked Against The Best
Tested with Yahoo Cloud Serving Benchmark - the industry standard for NoSQL databases
Throughput (ops/sec)
P99 Latency (lower is better)
YCSB Workload Results
| Workload | Read/Write | Throughput | Avg Latency | P99 Latency |
|---|---|---|---|---|
| Workload A | 50% / 50% | 33,830 ops/sec | 453 µs | 1.7 ms |
| Workload B | 95% / 5% | 34,341 ops/sec | 450 µs | 1.7 ms |
| Workload C | 100% / 0% | 29,913 ops/sec | 517 µs | 2.4 ms |
| Load (Insert) | 0% / 100% | 11,628 ops/sec | 1,338 µs | 4.6 ms |
MongoDB-Comparable
Similar throughput with better P99 latency than MongoDB
Sub-2ms Latency
Consistent low latency even at P99 percentile
~200KB Footprint
10x smaller than MongoDB while delivering similar performance
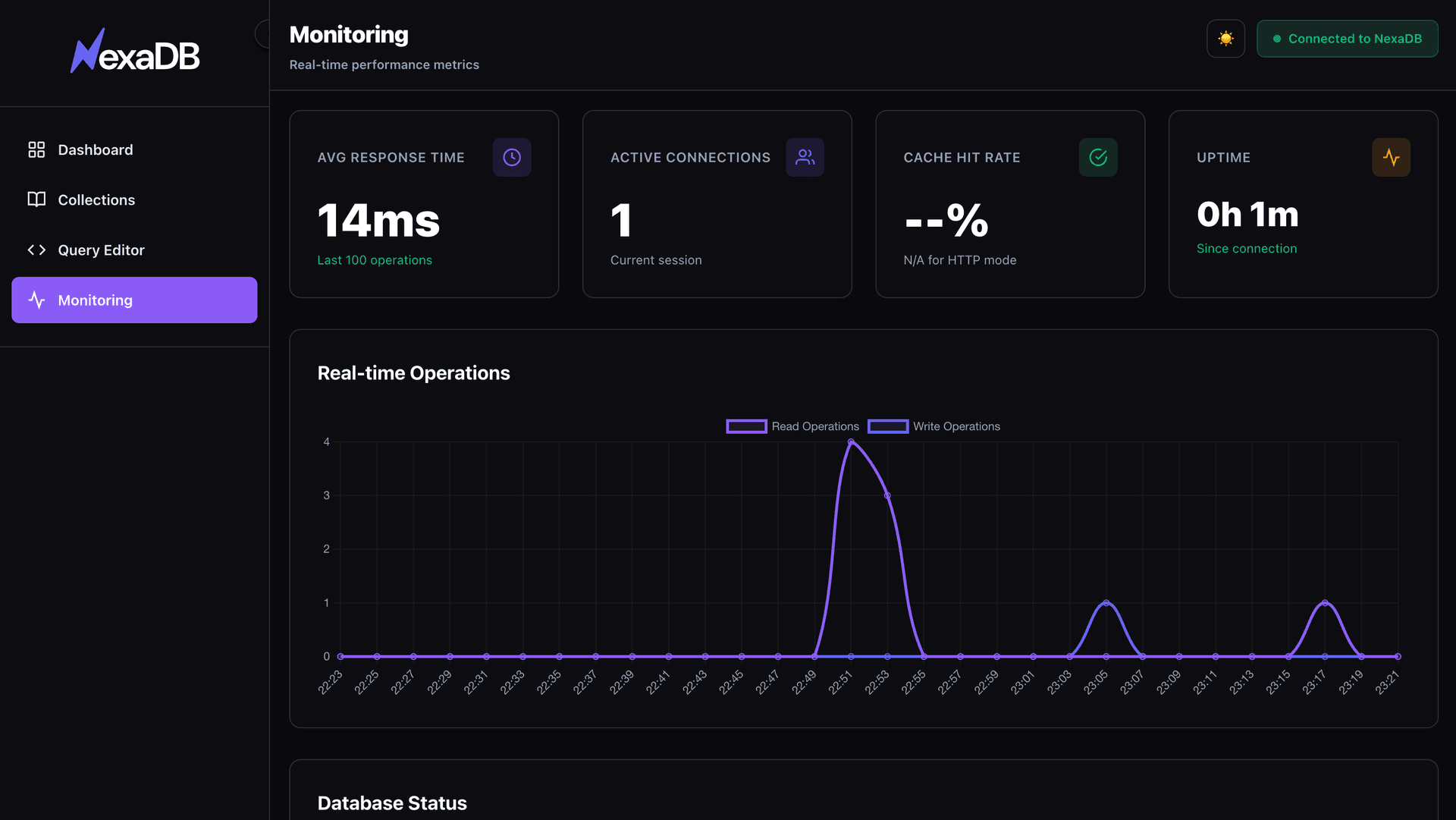
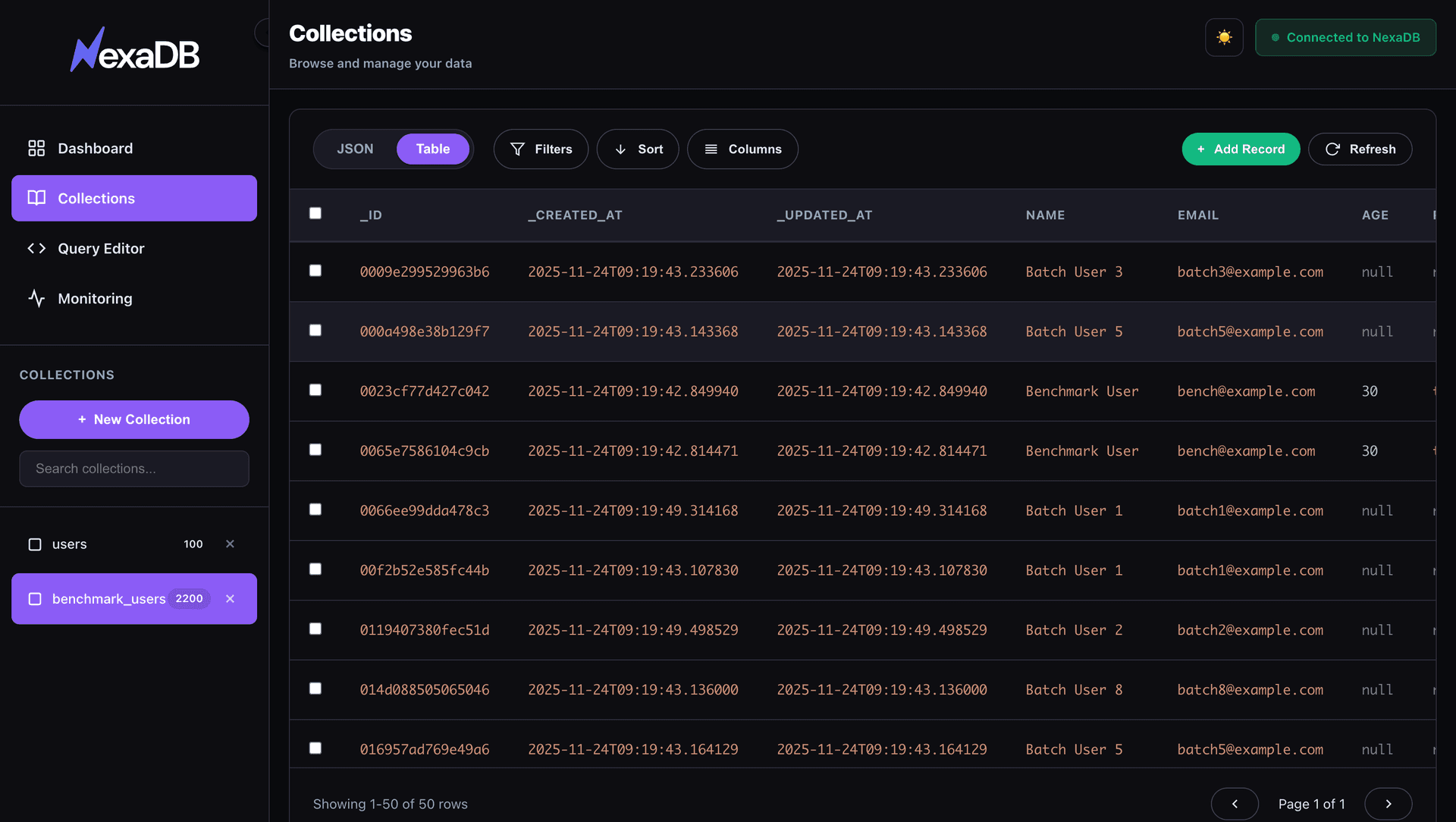
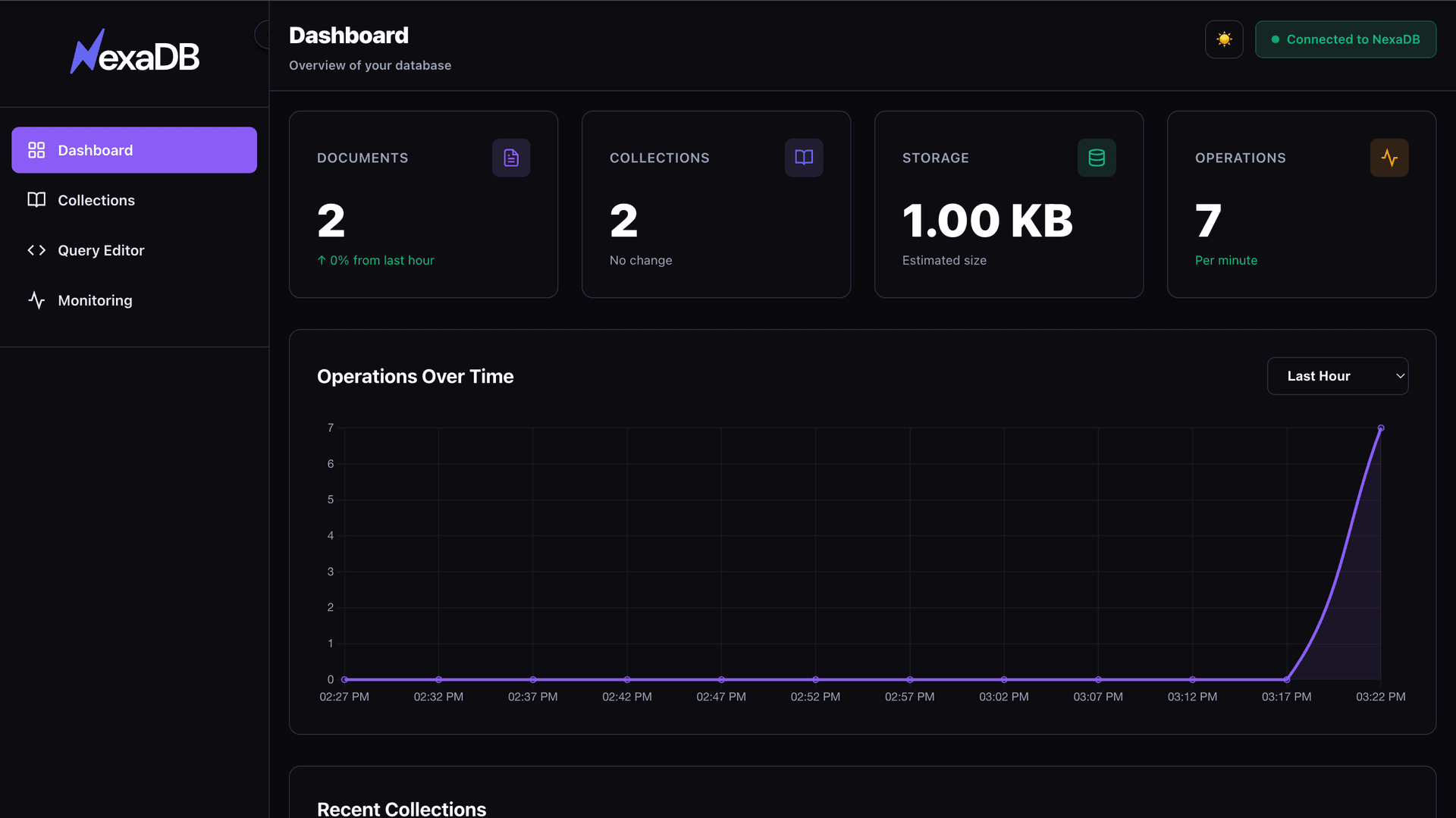
Manage Your Data
Visually
Beautiful, modern admin interface with TOON export included. Access at http://localhost:9999
Build Your First AI App
From zero to semantic search in 5 minutes. No ML expertise required.
Install NexaDB
One command. No Docker. No config files. Done.
brew install nexadbWhy Developers Love NexaDB
Built for speed, simplicity, and AI apps. Not trying to replace MongoDB - just better for rapid development.
Perfect For
MVPs & Prototypes
Ship in hours, not days. Zero config, admin panel included, fast enough for production. Perfect for hackathons and proving concepts quickly.
AI & RAG Apps
Vector search + TOON format = perfect for ChatGPT wrappers, semantic search, and AI chatbots. Save 40-50% on LLM costs instantly.
Fast-Moving Startups
Build fast, iterate faster. When you need to ship features daily and MongoDB feels like overkill. Production-ready but not over-engineered.
Start Building
Simple API with TOON format support - Python and JavaScript clients available, Java coming soon
const { NexaClient } = require('nexaclient');
const client = new NexaClient({
host: 'localhost',
port: 6970,
username: 'root',
password: 'nexadb123'
});
await client.connect();
// Export in TOON format (40-50% fewer tokens)
const { toonData, stats } =
await client.exportToon('users');
console.log('Token Reduction:',
stats.reduction_percent + '%');from nexaclient import NexaClient
client = NexaClient(
host='localhost',
port=6970,
username='root',
password='nexadb123'
)
client.connect()
# Export in TOON format
toon_data, stats = client.export_toon('users')
print(f"Token Reduction: {stats['reduction_percent']}%")// Spring Boot auto-configuration
@Service
public class UserService {
private final NexaClient client;
public UserService(NexaClient client) {
this.client = client;
}
public String createUser(String name) {
Map<String, Object> user =
Map.of("name", name);
Map<String, Object> result =
client.create("users", user);
return (String) result.get("document_id");
}
}Ready to save
40-50% on LLM costs?
Join developers building AI applications with NexaDB and TOON format